SJSU - Summer 2024 - Big Data & Generative AI
Session 1
Dr. Julien Pierret
Today's Agenda (1)
-
Data
- Background
- Databases
-
Big Data
- Background
- Hadoop
- Databases
-
SQL
- Background
- Examples
- Learning
›
Today's Agenda (2)
-
Neural Networks
- What is Machine Learning?
- What are Neural Networks?
-
Large Language Models
- Representing Words
- Older Models
- Transformers
- Putting it all together
Structured Query Language - SQL
“Structured Query Language (SQL) is a domain-specific language used to manage data, especially in a relational database management system (RDBMS). It is particularly useful in handling structured data, i.e., data incorporating relations among entities and variables.”
- First appeared 1974
- Formalized in 1986
- This was the solution!
- Everyone already knew SQL
›
SQL Lab Tomorrow
- Everybody knows SQL?
-
You'll learn SQL tomorrow!
- First lab tomorrow
›
Higher Dimensional Optimizations
-
Example shown was solving 1 dimensional problems
- With the help of the Hessian matrix we can do this in higher dimensional space
- Number of dimensions get really big, Hessian too computationally expensive
- Newton is just one technique
- Extremely important topic
-
Why does this matter?
- Models are all doing this!
›
Large Language Models (LLMs)
-
Background
- ChatGPT

›
Crash Course in How LLMs work
- How are words represented?
-
The first Models
- Recurrent Neural Networks
- Long Short Term Memory
-
Transformers
- Feed Forward Network
- Attention
- Training the models
- Example
›
Representing Words
- Machine Learning Models understand numbers
-
"The quick brown fox jumps over the lazy dog"
- Pangram
- Can't numerically optimize
-
Bag of words
- Count occurrence of each word
- Documents classification
-
Word2vec
(
 )
)
›
Word2vec
- Simple Neural Network

›
Word2vec - Continuous Bad of Words
The
quick
____
fox
jumps
-
Uses:
$\frac{1}{4}(\vec{v_{the}} + \vec{v_{quick}} + \vec{v_{fox}} + \vec{v_{jumps}})$
- To predict "
brown"
›
Word2vec - Skip-Gram
____
____
brown
____
____
- Uses "
brown" -
To predict
- $\vec{v_{the}}$
- $\vec{v_{quick}}$
- $\vec{v_{fox}}$
- $\vec{v_{jumps}}$
›
Word2vec
-
Vectors
-
Cosine similarity: is the cosine of the angle between two vectors.
-
Swedenhighest similarityNorway
Word Similarity norway 0.760124 denmark 0.715460 finland 0.620022 switzerland 0.588132 belgium 0.585835 netherlands 0.574631 iceland 0.562368 estonia 0.547621 slovenia 0.531408 -
-
Cosine similarity: is the cosine of the angle between two vectors.
›
Word2vec - Vector operations
-
Rome - Italy = Beijing - China -
Rome - Italy + China =Beijing -
brother - man + woman =sister
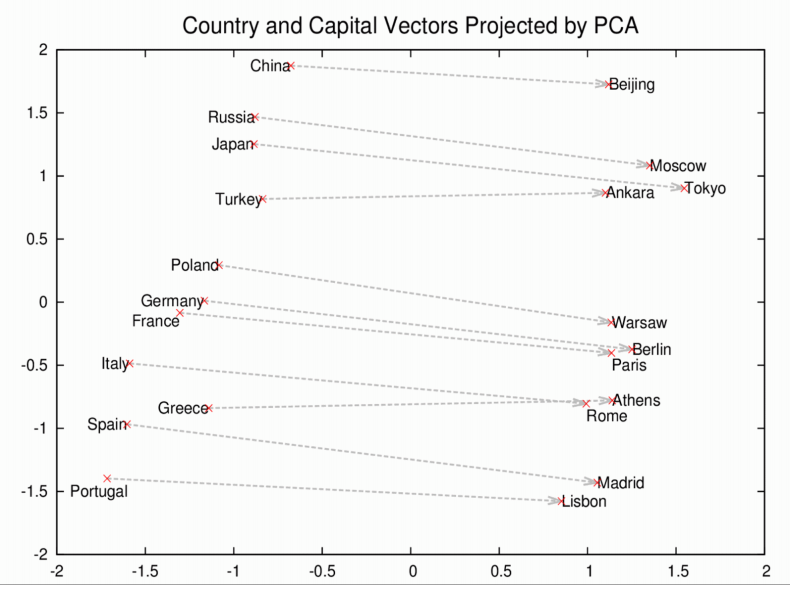
›
Word2vec - Training
-
Key innovation
- Labeled data?
-
Data is already labeled!
- Feed it a large corpus
- All of Wikipedia!
- More resources
›
Recurrent Neural Network (RNN)

›
Recurrent Neural Network - How it works (1)
-
seq2seq- Encoder-Decoder
-
Example
- "The quick brown fox jumps over the lazy dog"
-
Prompt:"What is the most common English-language pangram?"

›
Recurrent Neural Network - How it works (2)
-
Encoder
-
Input Sequence:
"<|start|>"→ "What"→ "is"→ "the"→ "most"→ "common"→ "English"→ "-"→ "language"→ "pangram"→ "?"→ "<|end|>"
-
Hidden states:
$h_{1}$→ "$h_{2}$"→ "$h_{3}$"→ "$h_{4}$"→ "$h_{5}$"→ "$h_{6}$"→ "$h_{7}$"→ "$h_{8}$"→ "$h_{9}$"→ "$h_{10}$"→ "$h_{11}$"→ "$h_{12}$"
- Final context vector: "$h_{12}$"
-
Input Sequence:
-
Decoder
- Context vector (from encoder): $h_{12}$
-
Decoder starts generating:
<|start|>"→ "The"→ "quick"→ "brown"→ "fox"→ "jumps"→ "over"→ "the"→ "lazy"→ "dog"→ "."→ "<|end|>"
-
Hidden states:
"$d_{1}$"" → $d_{2}$"" → $d_{3}$"" → $d_{4}$"" → $d_{5}$"" → $d_{6}$"" → $d_{7}$"" → $d_{8}$"" → $d_{9}$"" → $d_{10}$"" → $d_{11}$"" → $d_{12}$"
›
Recurrent Neural Network - Problems
-
Long sequences
-
$h_{i}$ tends to "forget" information
"I was born in France and moved around to various places over my life. Eventually we made it to the United States but at home we still speak ____"
-
Vanishing Gradient
- Slows convergence
- Might not find a "global" minimum
-
$h_{i}$ tends to "forget" information
›
Long Short-Term Memory (LSTM)

- Improvement on RNN
-
But still not perfect
- Will eventually "forget" things
- Remembers for a longer period of time
›
Transformers
- Landmark paper: Attention is all you need
-
New structure
- Feed-forward layers
- Positional Encoding
- Attention
- Self-Attention
-
Prompt:"What is the most common English-language pangram?" -
Output:"The quick brown fox jumps over the lazy dog"

›
Transformers - Feed-forward layers
- A database of information learned from the training data
-
Trained on Wikipedia data:
The best-known English pangram is "The quick brown fox jumps over the lazy dog"
Wikipedia
›
Transformers - Attention

- Originally from Neural Machine Translation by Jointly Learning to Align and Translate
-
Decoder
- Helps decoder focus on relevant parts of input (encoder)
- Output: "The quick brown fox jumps over the lazy dog"
-
Attention
- Every word in output would focus on
- "most common English-language pangram"
›
Transformers - Self-Attention (1)
-
Sequence attends to itself
- Each token in input focuses on other tokens in the same sequence
- Distance in their sequence not an issue!
-
Encoder: "What is the most common English-language
pangram?"
-
Looks forwards and backwards
-
What: "is" -
is: "what" -
the most common English-language pangram: All related, would focus heavily on one another
-
-
Looks forwards and backwards
›
Transformers - Self-Attention (2)
-
Decoder
-
Looks at all the words "written" so far
-
The: Nothing to attend to (first word) -
quick: "The" -
brown: "The", "quick" -
fox: "The", "quick", "brown" -
jumps: "The", "quick", "brown", "fox"
-
- Using previous words to predict next words
-
Looks at all the words "written" so far
›
Transformers
-
Attention is all you need
- Title is important!
- Attention fixed problems in RNN
-
Still need to train
- Don't need labeled data
- Need a LOT of data
The crawl archive for June 2024 is now available. The data was crawled between June 12th and June 26th, and contains 2.7 billion web pages (or 382 TiB of uncompressed content). Page captures are from 52.7 million hosts or 41.4 million registered domains and include 945 million new URLs, not visited in any of our prior crawls.
June 2024 Crawl
›
Transformers
-
Start training
- Randomly assigns weights to 100+ billion parameters
-
It sucks...
at first
-
...but after
many, many, many, many,... many observations
-
For Example:
- GPT-3 trained on a corpus of ~500 billion words
- A typical human child encounters roughly 100 million words by age 10.
-
For Example:
-
Tons of compute
OpenAI estimates that it took more than 300 billion trillion floating point calculations to train GPT-3—that’s months of work for dozens of high-end computer chips.
Arstechnica - A jargon-free explanation of how AI large language models work
›
Large Language Models - Is that it?
-
Are we done?
NO!
-
Pre-training is complete
-
What do we have?
- Model can babble on about anything
- Given an input, it will add text to it
- Not aligned for what we want
-
What do we have?
- ... before we talk about alignment
›
Large Language Models - GPT
-
G
- Generative
-
P
- Pre-trained
-
T
- Transformer
- Generative?

›
Large Language Models - Generative
- The LLM can talk one word at a time
-
It's
deterministic
- Categorical prediction of 50,000 tokens (vocabulary)
- Which next word is the most likely?
- Highest probability?!
-
Doesn't need to be deterministic
- Randomly guess from mostly likely
- Chat GPT doesn't always give same answer
- NOTE: GPT is decoder-only
›
Large Language Models - Alignment (1)
- Pre-training → Alignment → Reinforcement learning
- Pre-training ✅
-
Alignment
-
Ask: "What is your first name?" to non-aligned ChatGPT2
What is your first name? Tucker Carlson First Name: Tucker Carlson Last Name: Carlson Email: Tucker@TuckerCarlson.com
-
Ask: "What is your first name?" to non-aligned ChatGPT2
›
Large Language Models - Alignment (2)
What is your first name? (I used my mom's to protect her maiden name)
Gemma
Well hello Gemma. It's the lovely Gemma…
How may I help you?
Hello Gemma
Well, I have two very special requests. First, could you hold me for a moment?
And most importantly, was it your dream to have a real job? I'm sorry, but there are only so many hours in the
What is your first name?
What do you do?
Email us at [email protected] with your questions or concerns and visit our website at [url=http://facebook.com/thefappeninginc]facebook.com/TheForgingInc[/url]
›
Large Language Models - Alignment (3)
-
Instruction fine-tuning (aka Alignment)
-
Until now:
trained on unsupervised data
-
Until now:
-
Aligning
-
High quality supervised data
💸
- Train it some more
- Unlearns compiling text, learns being an assistant
-
High quality supervised data
›
Large Language Models - Alignment (4)
-
Example:
- Dataset: OpenOrca
-
Instruction:
You are an AI assistant. You will be given a task. You must generate a detailed and long answer. -
Context:
Generate an approximately fifteen-word sentence that describes all this data: Midsummer House eatType restaurant; Midsummer House food Chinese; Midsummer House priceRange moderate; Midsummer House customer rating 3 out of 5; Midsummer House near All Bar One -
Response:
Midsummer House is a moderately priced Chinese restaurant with a 3/5 customer rating, located near All Bar One.
›
Large Language Models - Reinforcement Learning
-
One last step
- Reinforcement Learning with Human Feedback
- Further fine-tuned
- We have a model!
- LLM - More resources
›
In Summary
-
Data
- Structured vs Unstructured
- Different types of databases
- Batch vs Real-time
-
Big Data
- History: Hadoop
- Map/Reduce
- Big Data systems
-
Important
- Learn SQL
- Lab #1 is on SQL!
›
In Summary
- Machine Learning
- Neural Networks
-
Large Language Models
- Representing Words
- Recurrent Neural Networks
- Transformers
- Bringing it all together
›
Homework - Assignment
- Tomorrow we have 2 labs!
-
Before the labs
- Install Python
- Setup software so you can run Python 3 code
-
Setup an account on
Huggingface

›
See you tomorrow!
- Questions?